WWDC 21 - 探索使用 VideoToolbox 进行低延迟视频编码
低延迟编码对于很多视频 app 来说都很重要,特别是对实时音视频场景。苹果在 WWDC 2021 在 VideoToolbox 里推出了一种新的低延迟编码模式。低延迟编码模式的主要目的是为实时通讯场景优化现有的编码流程。
低延迟视频编码有以下的特点,从而对一个实时视频通讯 app 进行优化。
- 处理效率高,最小化端到端的延迟
- 新增两种 profile:
CBP&CHP,增强互操作性 - 引入时域伸缩编码 (
Temporal Scalability),当会话中有多个参与者的时候,提供高效的编码流程 - 支持设置最大帧量化参数 (
Max Frame QP),展示最好的视频质量 - 引入长期参考帧
LTR,提供一个可靠的机制从网络丢包错误中恢复通讯
1. 低延迟视频编码一览
下图是苹果平台上视频编码管线的简图:
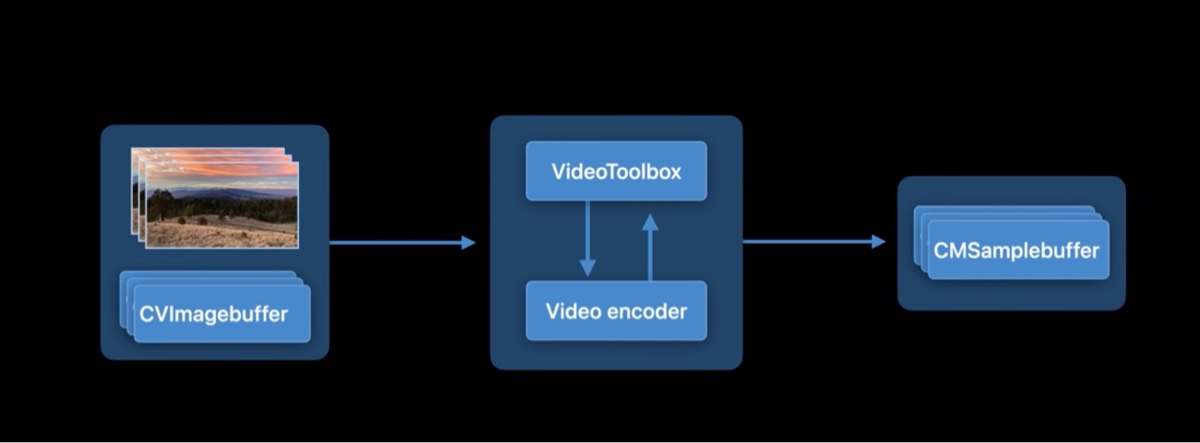
CVImageBuffer里包含的是从摄像头采集到的原始图片,作为输入传递给VideoToolbox- 然后
VideoToolbox把原始图片交给Video Encoder进行压缩编码 (比如 H.264) 来降低视频体积 - 压缩编码之后的视频数据被包在
CMSampleBuffer里,接着通过网络传输到服务器或者 CDN 上
从这个图上我们可以知道,端到端延迟可能会受两方面的影响:编码处理时间 和 网络传输时间,为了最小化处理时间,低延迟模式去掉了帧冲排序(frame reordering,移除 B 帧),遵循一帧进,一帧出的编码模式。此外,这种模式下,码率控制器对网络变化的感知更加敏感,能更快速的响应,这样也能最小化由网络拥塞带来的延迟。在这两个优化的加持下,对比默认模式,低延迟模式有着明显的提升,能够在 720P 30fps 的视频中最多减少 100ms 的延迟。在视频会议中,节省出来 100ms 延迟至关重要。
低延迟模式下总是会使用硬编来节省电量,需要留意的是,此模式下只支持 H.264 编码,支持 iOS 和 macOS 双平台.
2. 如何开启 VideoToolbox 低延迟模式?
我们先来看一下,此前我们是如果使用 VideoToolbox 进行视频帧编码的。
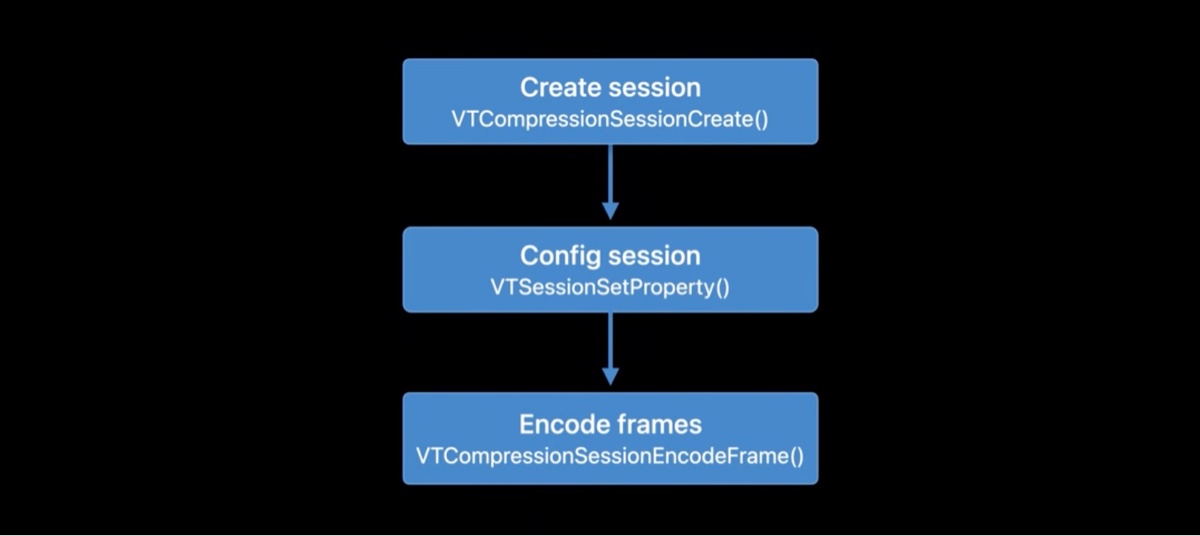
- 首先创建 一个
VTCompressionSession - 使用
VTSessionSetProperty配置 Session - 调用
VTCompressionSessionEncodeFrame,传入CVImageBuffer编码视频帧,从outputHandler里取出编码后的结果数据
如何开启低延迟模式呢?很简单,只涉及到创建 Session 这一阶段,设置 kVTVideoEncoderSpecification_EnableLowLatencyRateControl 属性为 true 即可。代码如下:
1 | CFMutableDictionaryRef encoderSpecification = |
创建完 VTCompressionSession 之后,还可以通过配置 kVTCompressionPropertyKey_AverageBitRate 控制编码的码率。
3. 低延迟模式的新特性
3.1 互操作性,引入 2 个新的 Profile
Profile 定义了一组编码器支持的编码算法,为了能够和接收方进行通讯,发送方的编码后的比特流须顺从接收方的支持解码器支持的 profile. 目前 VideoToolbox 支持三种 profile:
Baseline profileMain profileHigh profile
从上到下,算法越来越复杂,编码时间越长,压缩比越高。
今天新增了两种 profile 进来:
Constrainted baseline profile (CBP), 主要用于低能耗场景Constrainted high Profile (CHP),有着更先进的算法,提供更好的压缩比
可以简单地通过设置 Session 的 ProfileLevel 属性为 ContrainedBaseLine_AutoLevel 来申请使用 CBP,同理,设置为 ContrainedHigh_AutoLevel 申请使用 CHP,参考代码如下:
1 | // Request CBP |
3.2 时域可伸缩性(temporal scalability)
在开始之前,先简单介绍一下 SVC(Scalable Video Coding),SVC 是 H.264 标准的一部分 (Annex G),SVC 分为两类,时域可伸缩编码 和 空域可伸缩编码。
时域可伸缩编码主要通过调节视频帧率,在基础层帧率和增强层帧率之间提供可伸缩性。空域可伸缩编码是可以把视频按不同分辨率进行分层,基础层是低分辨率图像,增强层提供更高的分辨率,在不同的分辨率之间提供可伸缩性。
OpenH264 目前是支持 SVC 的,X264 还不支持,这次苹果在 VideoToolbox 引入的就是 SVC 里的时域可伸缩编码,这对苹果生态平台上视频领域来说,是很关键的一项技术支持。
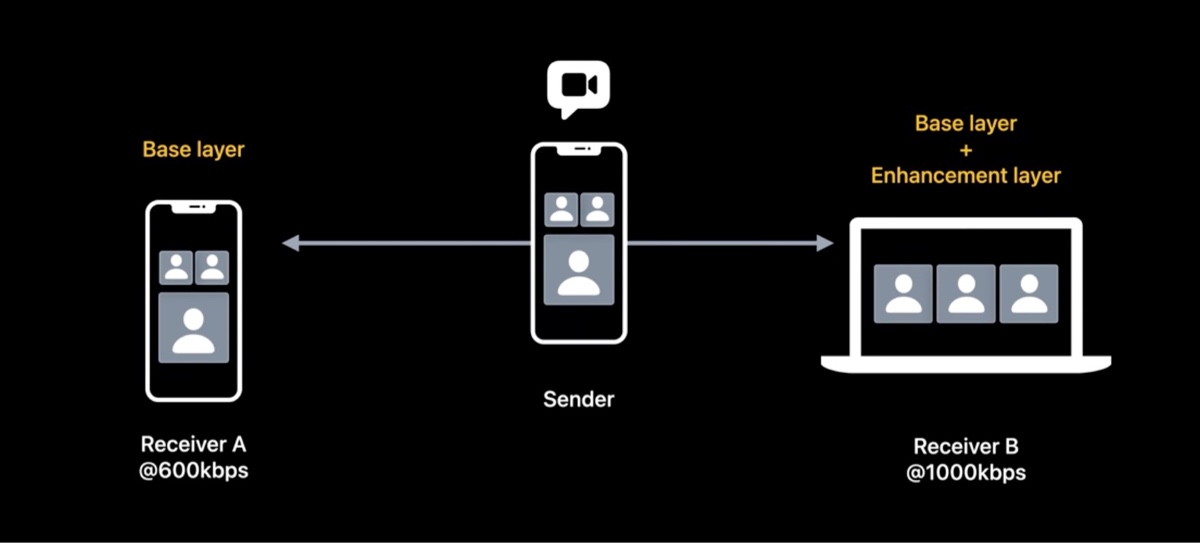
考虑一个这样的三方视频通话场景,接受者 A 只有 600kbps 的带宽,接受者 B 有 1000kbps 的带宽。那么正常情况下为了满足接收者的下行带宽,发送者需要编码两路流,一路低码率,发给 A,另外一路高码率,发送给 B。但这样不并不是最优解。
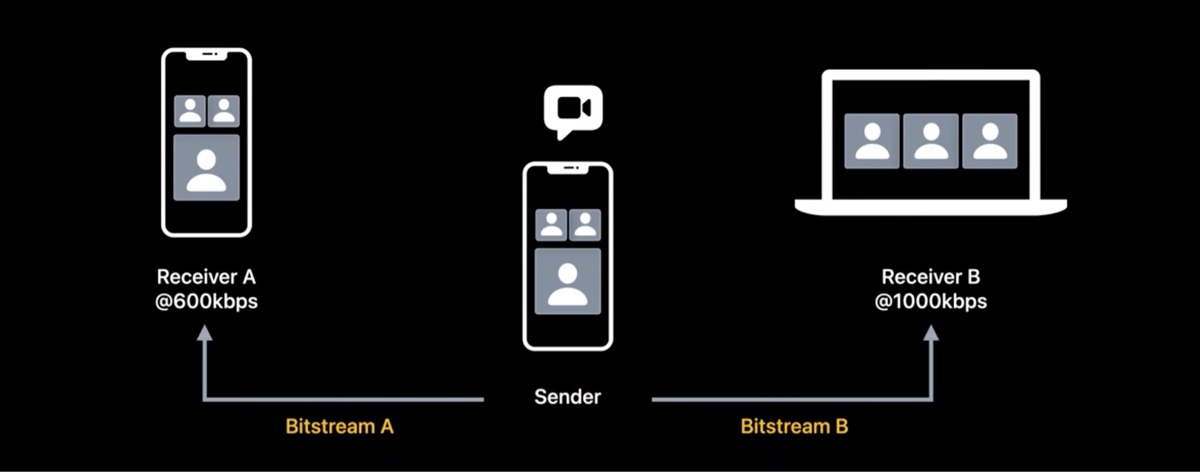
这种场景下,时域伸缩可以更高效。发送者只需要编码一路流,然后分为两层来使用。
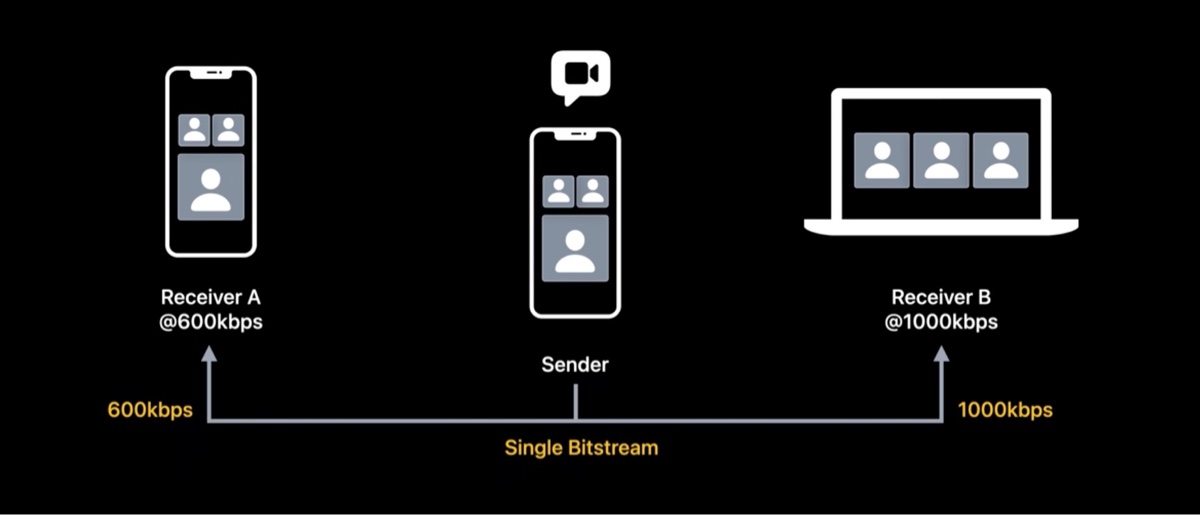
这是怎么做到的呢?我们来一步一步看。下图是一组编码后的视频帧,每一帧都饮用亲一帧作为参考帧。

然后我们从中抽取一般的帧,放到第二层里,然后修改参考帧,只有第一层的帧能作为预测参考帧。我们称第一层为基础层(Base Layer),第二层为增强层(Enhancement Layer),Enhancement Layer 作为 Base layer 的增补,可以提高帧率。

我们再回到刚才的问题,发送者可以只发送 Base Layer 数据给 A,因为 Base layer 本身是自洽可解码的。而且因为只有一半的视频帧,所以整体码率也会较低。
对于 B,因为他有更高的带宽,发送者可以把 Base Layer 和 Enhancement Layer 的数据都发给他。这样 B 就能享受更丝滑的视频体验。
此处(10:00),演讲者分享了两段自己录制的视频,一段是只有 Base Layer 的视频,可以看出第一段有一些顿挫感,不过也是可以接受的。第二段是完整 Layer 的视频,有更高的帧率,观看体验确实更顺滑。

第一段帧率只有完整帧率的一半,码率占完整的 60%,这两段视频只需要编码器编码一次,在多方视频会议场景下,性能上能带来很大的提升。
时域伸缩的另外一个好处是错误恢复能力,因为所有的 Enhancement Layer 的帧都不会用于预测参考帧,就是说没有其他帧依赖他们。也就意味着即便这些帧在网络传输中因为一些原因丢掉了,其他帧也不会受影响,这会使整体视频会议的鲁棒性更高。
如何开始时域伸缩呢?苹果新增了一个几个 property:
- 创建 Session 时,通过
kVTCompressionPropertyKey_BaseLayerFrameRateFraction设置 Base Layer帧率占比,剩余的帧率会留给 Enhancement Layer - 通过检查 SampleBuffer 的
CMSampleAttachmentKey_IsDependedOnByOthers来检查 layer 的信息,如果是 Base Layer 的视频帧,取到的值为 true,Enhancement Layer 为 false - 前面提到过 使用
kVTCompressionPropertyKey_AverageBitRate来设置总体目标码率,设置完之后,可以通过kVTCompressionPropertyKey_BaseLayerBitRateFraction设置 Base Layer 的码率占比,默认为 0.6,也就是 60% 的码率分配给 Base Layer,苹果建议该值设置在 [0.6, 0.8] 范围。
3.3 最大帧量化参数 (Max frame quantization parameter)
量化参数,简称 QP,用来调节图片质量和码率的。低 QP 会生成高清晰度的图片,图片的大小会比较大。反过来高 QP 会带来低质量,体积更小的图片。
低延迟模式下,编码器会综合考虑图片复杂度、输入帧率、视频运动等因素来调整 QP,从而在目标码率的限制下,编码出最高质量的图片。苹果鼓励在这方面依赖编码器的默认行为。
有些场景下,客户有视频质量有指定的诉求,这个时候可以通过控制最大帧量化参数来实现。编码器总是选择比最大 QP 小的值,所以客户可以细粒度的控制画面的清晰度。需要注意的是,此时码率控制器依然起着作用,当在编码器顶着最大 QP 的上限,码率却依然不够用的情况下,它会选择丢帧来维持目标码率。
这有一个能排上用场的例子,比如在弱网下要传输远程桌面视频,我们希望通过牺牲帧率来实现获得更清晰的画质。设置最大 QP 可以满足这个需求。
引入了 kVTCompressionPropertyKey_MaxAllowedFrameQP 来支持设置最大 QP,该值决定着此后所有编码帧的 QP 上限。根据标准,Max QP 的取值范围是 [1, 51].
3.4 引入 长期参考帧LTF, 提高错误恢复能力
LTF 是 long-term reference 的缩写,主要用于错误恢复。
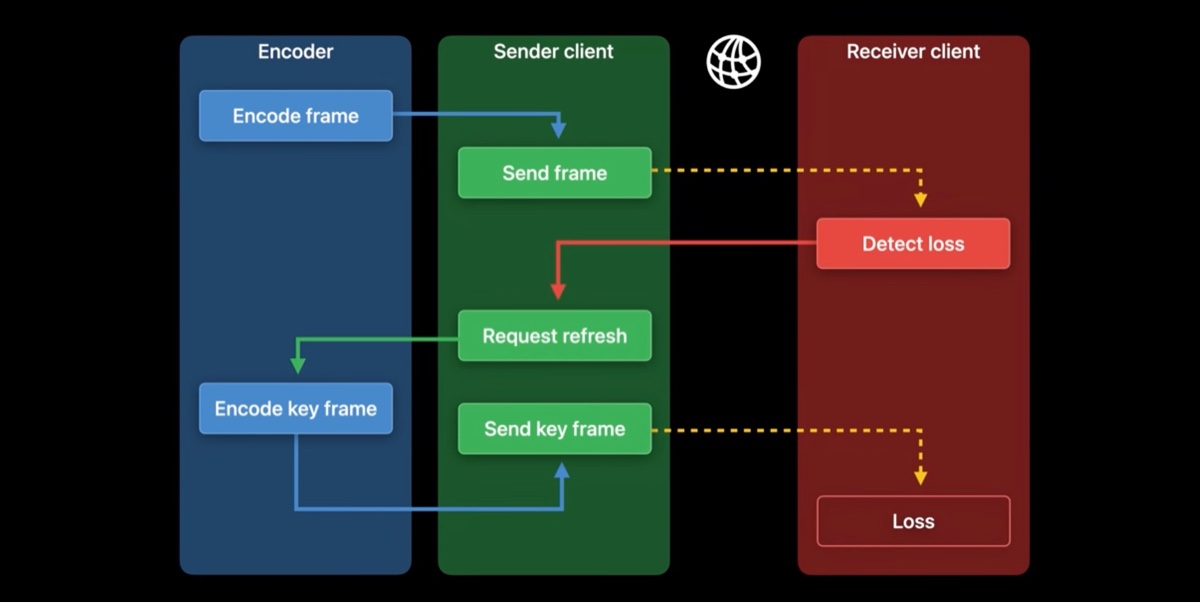
假设在弱网下进行着一场视频会议,如图,图中有三类参与者,编码器、发送端、接受端。当网络传输错误时可能会丢帧,当接受端检测到丢帧后,它会向发送端请求一个刷新帧以重置会话。编码器接收到请求之后,通常它会考虑到刷新的目的,编码出一个关键帧,而关键帧比较大,在弱网下会花费更长的时间才能到接受端,这可能会加重网络拥塞问题。
所以我们能否提供一个预测帧代替关键帧来实现刷新的目的?如果我们有帧级别的 ack 的话,就可以实现。
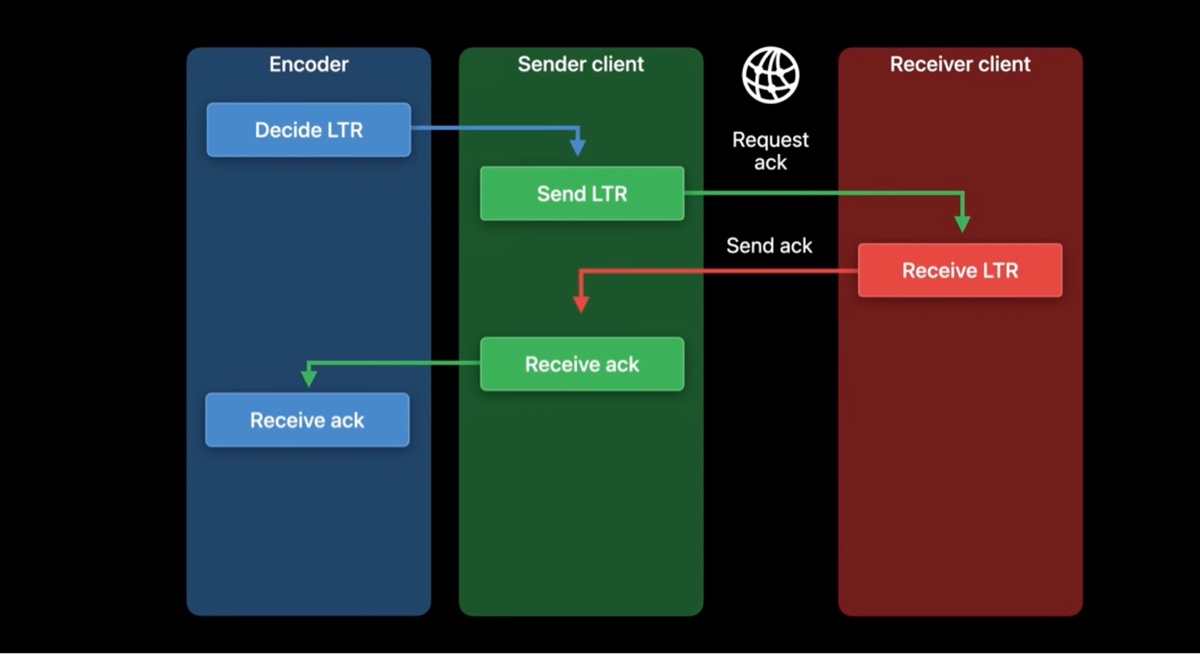
首先,我们要确定哪些帧需要对方 ack 确认,这些帧我们称之为 LTR 帧,决定权归属编码器。当发送端发送一个 LTR 帧后,它需要向接受端请求 ack 确认消息。当接受端收到 LTR 帧后,它就需要向发送端发回一个 ack 确认消息。一旦发送端收到 ack 之后,它就传递给编码器,编码器就知道了接受端已经收到了哪些 LTR 帧。
在这个基础上,我们再看一下刚才弱网下的问题。
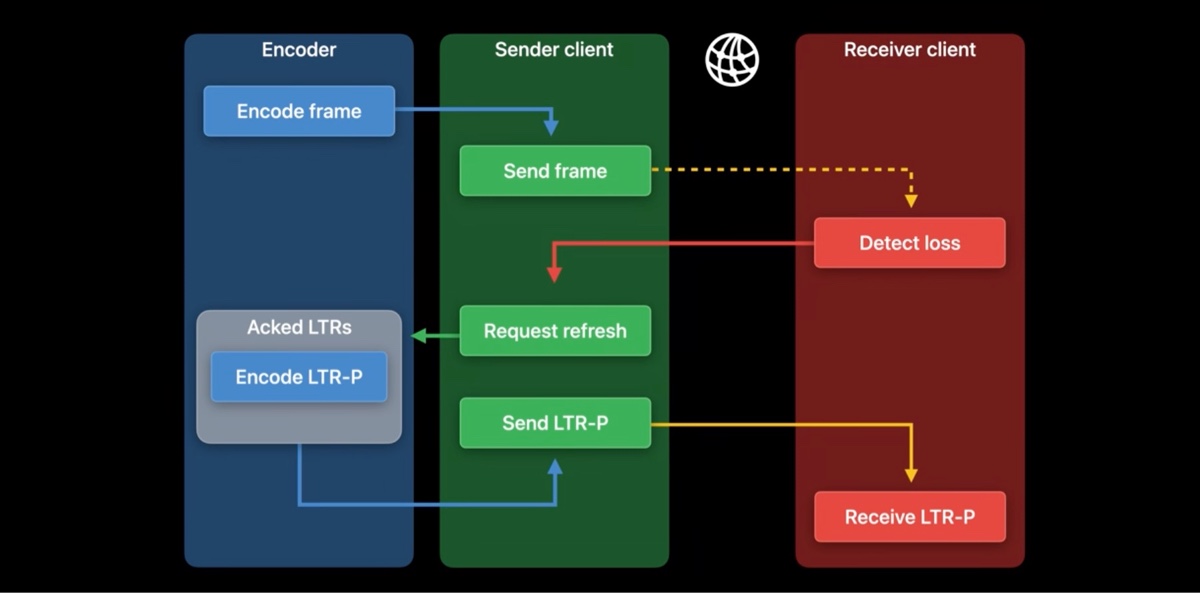
当编码器收到刷新请求后,因为此时编码器已经有一些已经确认的 LTR,所以编码可以可以从这些 LTR 中预测编码出一帧,这样编码出来的帧我们称之为 LTR-P 帧。通常 LTR-P 帧比关键帧要小很多,所以它也更容易被传输。
现在我们看看 LRT 的 API 支持。需要注意的是,发送端和接受端之间的帧 ack 确认需要在应用层处理,可以通过一些机制来实现,比如 RTCP 协议的 RPSI 消息(RPSI 全称是 Reference Picture Selection Indication )。
这次我们主要关注编码器和发送端在这个过程中如何交互。一旦启用了低延迟编码,就可以通过设置 kVTCompressionPropertyKey_EnableLTR 来开启 LTR.
当编码出一帧 LTR 后,编码器会在 SampleBuffer 的 kVTSampleAttachmentKey_RequireLTRAcknowledgementToken 里存放一个唯一的 frame token 值(蓝色箭头)。然后发送端能从 SampleBuffer 里拿到 LTR ack token,通过前面提到的应用层机制,发送给接受端,接受端收到之后,把 ack 的 token 发回发送端。
发送端负责把接收端 ack 的 LTR 帧 报告给编码器(绿色箭头),对应的 API 是 kVTEncodeFrameOptionKey_AcknowledgedLTRTokens 帧属性。因为可能一次会有多个 ack,所以这里需要一个数组来存储这些 token。
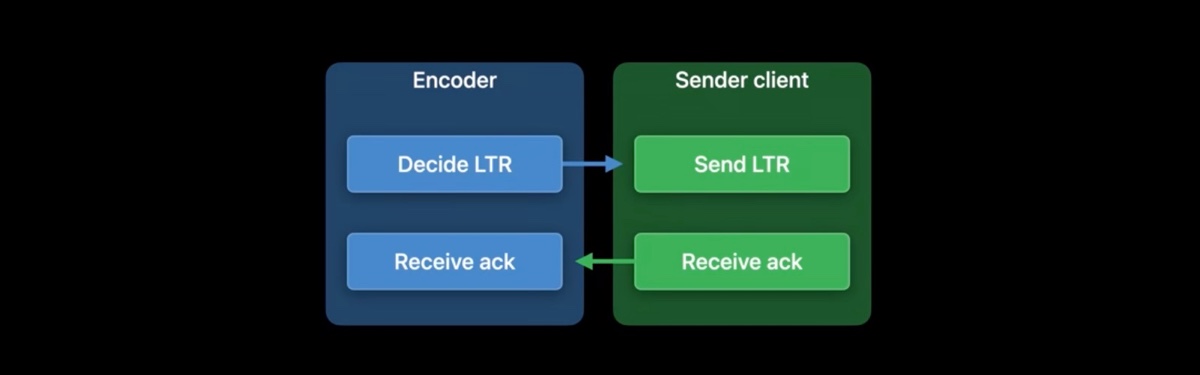
可以随时通过 kVTEncodeFrameOptionKey_ForceLTRRefresh 帧属性来请求一个刷新帧,一旦编码器收到请求,就会根据之前已 ack 的 LTR 帧预测编码出一个 LTR-P 帧,如果没有可用的 LTR 帧供预测参考,编码器会 fallback 到原来的机制,生成一个关键帧。
4. 回顾
VideoToolbox引入了低延迟模式,通过VTCompressionSessionAPI 开启低延迟模式- 低延迟模式的特性
- 处理效率高,延迟低
- 新增两种 profile: CBP & CHP
- 时域伸缩性
- 最大帧量化参数
- 长期参考帧 Long-term refernece
我的博客即将同步至腾讯云 + 社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=1hiagj0e99blg