AArch64 学习 (一) 基础指令,内存布局,以及基础栈操作
1. 什么是 ARM?
正式开始之前,我们先来了解一下什么是 ARM, 以及对应的一些概念.
Wikipedia 上是这么介绍 ARM 的:
ARM (stylised in lowercase as arm, formerly an acronym for Advanced RISC Machines and originally Acorn RISC Machine) is a family of reduced instruction set computer (RISC) instruction set architectures for computer processors, configured for various environments.
ARM 是 高级 - RISC (精简指令集)- 机器 的缩写,是精简指令集架构的家族。同时 Arm Ltd. 也是开发和设计、授权这项技术的公司名称.
1.1. 有哪些指令集架构呢?(TRDR, 可跳过)
目前用的比较多的架构是 ARMv7 和 ARMv8, 这两个名字各自都是一个系列.
在 ARMv7 以及之前都是最多支持 32 位架构 (更早还有 16 位,甚至更低), 那么 32 位架构对应的 ISA 也就是指令集称为 A32. 32 位下指令的地址空间最大只有 4GB, 苹果系列的代表是 iPhone 4 使用的 A4 芯片,以及 iPhone 4s 使用的 A5 芯片.
2011 年面世的 ARMv8-A 架构增加了对 64 位地址空间的支持,对应的 ISA 称为 A64. 这里用的词是 “增加”, 也就意味着在支持 32 位的基础上增加了对 64 位的支持。所以也可以看出来所谓的 32/64 位指的就是可寻址的最大地址空间。苹果系列从 iPhone 5s 开始的 A7 芯片一直到 A15, 以及 Apple M1 系列开始都是基于 ARMv8.x-A 规范的.
那我们见到的 AArch64 是什么呢?其实它和 AArch32 被称为 “执行状态” (execution state), 那么我们可以说 ARMv8-A 同时支持 AArch32 和 AArch64 两种状态,在 AArch64 状态下,运行的是 A64 指令集.
这里要注意 ARMv7/ARMv8-A、AArch32/AArch64 以及 A32/A64 在概念上的的区别,但很多时候,描述的范围都挺笼统的,有些也是可以互相指代的,大家知道就好.
上面说到指令集,指令集是做什么用的呢?我们为什么要了解这些?
指令集本质上定义了 CPU 提供的 “接口”, 软件通过这些 “接口” 调用 CPU 硬件的能力来实现编程。编译器在这里起到很关键的角色,它把上层代码根据对应的架构,编译为由该架构支持的指令集对应的二进制代码,最终运行在 CPU 上.
对 C 系语言来说,我们说的跨平台,其实就是通过同一份源码在编译时,根据不同 target 架构指令集,生成不同的二进制文件来实现的.
1.2. 本系列的目的:为什么要了解 ARM 汇编指令?
对我们来说熟悉 ARM 汇编指令,我们就能知道我们平常写的代码背后的本质,以及背后的原理,从而写出更高效,更可靠的代码。主要是编译器内部对 C/C++ 概念的实现原理.
这个系列也是本着这个初衷展开,适合对 AArch64 不熟,或者熟悉 x86/64 的汇编,想了解 AArch64 的同学。而且对 C/C++ 语法或者特性背后实现感兴趣的同学.
我其实也是最近才开始捡起来,之前学习的 x86 汇编早就还给老师了。相当于一边学习一边总结吧。好处是我大概知道刚开始可能会遇到哪些问题,在此基础上,尽可能的减少阅读门槛,这不是一个手册,而是一个循序渐进,目的性很强的一个系列.
因为目前 Apple M1 芯片就是基于 ARMv8.x-A 的,我们为了方便试验,接下来都选择使用基于 ARMv8-A A64 指令集来做解释.
2. 认识 A64 指令集下的常用指令
ARM 使用的是精简指令集 (RISC, Reduced Instruction Set Computer), 相对的就是 x86/64 的复杂指令集 (CISC, Complex Instruction Set Computer).
2.1. RISC 的一些特点:
- 精简指令集提供的指令更简单,更基础一些,也就是说,和 x86/64 相比,同样的代码,生成的指令会多一些.
- 内存访问和计算是完全分离的. RISC 使用 load 读取内存数据到通用寄存器中,计算完之后通过 store 保存到内存中
2.2. ARM64 的约定:
- 每个指令都是 32 位宽
- ARM64 有 31 个通用寄存器: X0-X30, 每个都是 64 位。如下图 1, 低 32 位可以通过 W0-W30 来访问。当写入 Wy 时,Xy 的高 32 位会被置 0, 比如
ADD W0, W1, W2 - 提供 32 个 128 位的独立的寄存器,用于浮点数以及向量操作,如下图 2, Qx 表示 128 位,Dx 表示 64 位,以此类推.
- 执行 32 位浮点数计算:
FADD S0, S1, S2. - 也可以直接使用 Vx 的方式,此时表示的就是向量操作,如
FADD V0.2D, V1.2D, V2.2D
- 执行 32 位浮点数计算:
- 其他的寄存器:
- ZXR/WZR 不可写,始终为 0
- SP, Stack Pointer, 栈指针寄存器,load 和 store 的基址,指向栈顶
- X29 用来表示
FP Frame Pointer, 方法调用的时候,指向栈基址,用于方法调用后恢复栈. - X30 被用作
LR Link Register, 也可以通过LR来使用。在方法调用前,保存返回地址. - PC, Program Counter 寄存器在 A64 里不是通用寄存器,数据处理中不可用。等价写法是
ADR Xd, ., 点表示当前行,ADR 取地址,相当于取当前行的地址,也就相当于 PC 寄存器的值 - macOS 中 X18 被禁用
(图 1)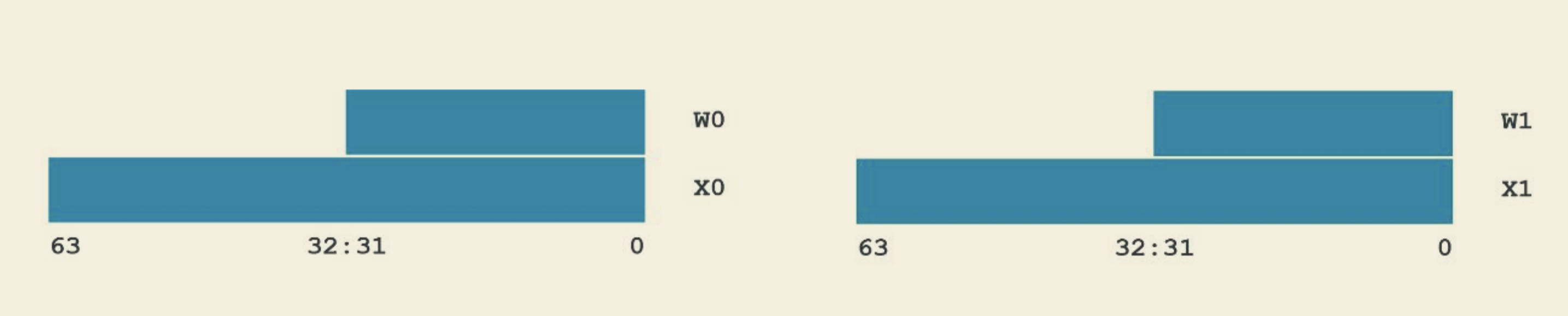
(图 2)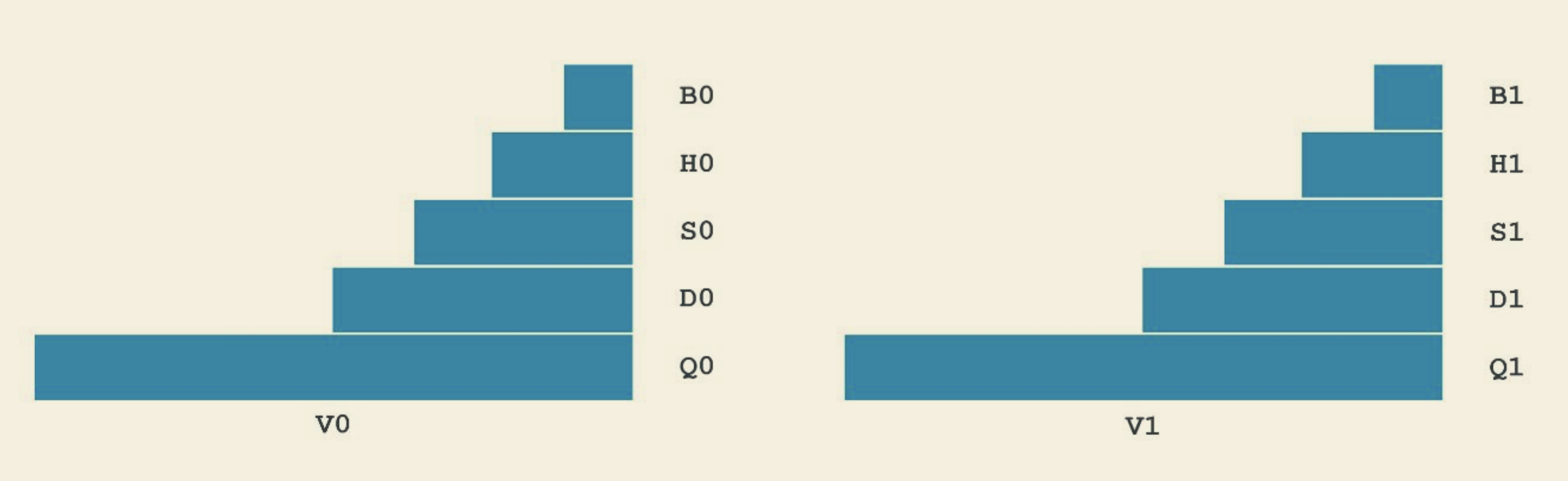
3. 一些常用基础指令的用法
指令的构成通常是这样的:
Operation Destination, Op1[, Op2 ..]
- Operation 描述指令的作用,比如 ADD 表示加,AND 进行逻辑与操作
- Destination 总是为寄存器,存放操作的结果
- Op1, 指令的第一个输入参数,总是为寄存器
- Op2, 指令的第二个输入参数,可以是一个寄存器,或者是常量值
不一定所有的制定规则都是这样的,为了减少理解的成本,我们先介绍几个简单却又必须的指令,其他的指令会在后面用到时再做介绍.
1 | // X1 存储了一个地址, 把 X1 寄存器里的地址对应的值, load 到 X0 寄存器中. 相当于 X0 = *X1 |
4. 进程内存布局
熟悉程序加载到内存之后的布局,对编写 / 阅读汇编代码至关重要,这里我们熟悉一下经典的内存布局,主要目的是方面理解后面的汇编代码。这里不展开西说,更详细的大家可以自行查询资料.
下面讨论的地址都是虚拟地址,虚拟地址最终会被操作系统映射到真实的物理地址中。所以我们也可以知道在 32 bit 指令集下,虽然寻址空间最大 4GB, 因为用了虚拟内存,实际上每个执行的进程都有 4GB 的寻址空间 (一般是 1G 内核空间,3G 用户空间), 并不是共享的.
当一个可执行程序被 load 到一个进程空间之后,内存布局如下。按段 (Segment) 来划分的,逐个来介绍.
- 最下面的是代码段,保存着二进制的代码,主要是各种函数,拥有只读和执行的权限。这个段的代码可以被执行,但是不可写入.
- 数据段,主要保存常量值或全局静态值,拥有只读权限,也是不可写入的.
- 堆,堆空间主要是用来动态分配内存的,我们用的 malloc, new 等申请的内存空间都会在这个区域,权限会读写。分配的虚拟内存地址由小增大,所以是向上增长的.
- 栈空间,栈空间主要是保存临时变量以及方法调用的参数。栈空间分配的方向是从大到小的,和 Heap 分配的方向是相对的。这么设计一方面是可以和 Heap 共用中间的待分配内存,另外一个原因是,每个方法里的临时变量所占用的内存在编译期其实就已经确定了,执行方法开始时一次性的分配所需的栈空间,执行结束一次性释放掉。其实堆空间和栈空间并没有物理上的差别,只是逻辑上定义如此.
- 内核空间,内核空间和栈空间一般还会有间隔,这里没画出来
1 | |--------------| |
5. 栈操作
栈操作是看懂汇编代码必备的,因为每个函数几乎都要开辟自己的一片栈空间,我们也称为 stack frame, 也就是我们常见到的 “栈帧”, 随着函数调用创建,函数结束调用释放销毁.
Stack frame 主要有两个基础用途,一个是存储临时变量,再者是函数调用和传参。后者会在后面的文章的讲述,这里我们主要看一下在没有函数调用的情况下栈空间的使用.
随便实现一个 test 函数,在 main 函数里调用它:
1 | long test() { |
如图 3, 在 GodBolt 里使用 armv8-a clang 11.0.1 编译器 生成汇编代码 (这里省略 main 函数):
(图 3)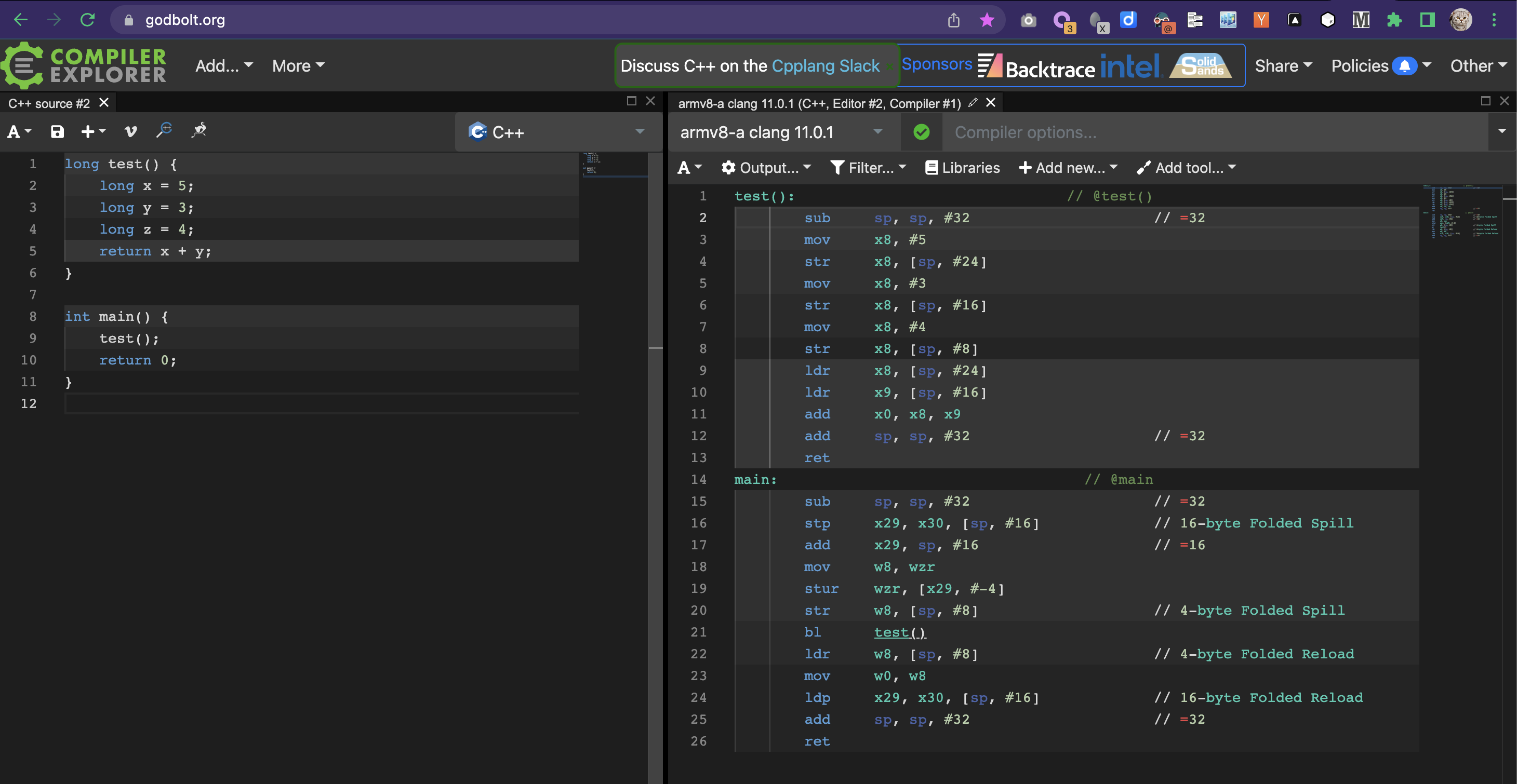
1 | test(): // @test() |
我们总结一下,其实也很简单,记住下面几个就够了:
- 每个函数内的栈空间大小,在编译期就已经确定
- 通过
sub sp, #size, 就是减小 sp 地址的方式分配栈内存,分配 size 字节.
ps: AArch64 要求每次分配的栈空间 size 必须是 16 bytes 的倍数 - 通过
add sp, #size, 就是增加 sp 地址的方式释放栈内存,释放的和开始分配的要一致 - 通过
str x寄存器, [sp, #offset]的方式 保存 数据到 栈空间 - 通过
ldr x寄存器, [sp, #offset]的方式 加载栈空间 数据到 寄存器